Ver código
#install.packages("data.table") #instalamos la librearía
library(data.table)#levantamos
num_cores <- parallel::detectCores()Los sociólogos y sociólogas son constructorxs de conocimiento, generadorxs de preguntas.
Programar no es solo un medio para manejar datos; es una extensión de nuestro análisis científico, permitiéndonos explorar, modelar y interpretar grandes conjuntos de datos con precisión y eficiencia. En la clase abierta de hoy, vamos a conocer en cómo R puede ser utilizado para profundizar nuestro entendimiento sobre procesos electorales, transformando datos crudos en información clara, útil y visual.
El procesamiento de microdatos electorales, especialmente a nivel de mesa, implica manejar volúmenes de datos que fácilmente alcanzan varios gigabytes. Esta magnitud de datos es un desafío insuperable para herramientas tradicionales como Excel o SPSS. Aquí es donde R, conocido por su robustez analítica, se convierte en una herramienta valiosa. Más allá de su capacidad para análisis complejos, R nos brinda la posibilidad de procesar grandes volúmenes de datos a través de código eficiente y personalizable.
Para consultar los datos inicialmente debemos acceder al portal del Estado Nacional donde se encuentra publicado el recuento de las últimas elecciones generales: https://www.argentina.gob.ar/dine/resultados-electorales/elecciones-2023. Aquí encontraremos los resultados oficiales de las distintas categorías en pugna.
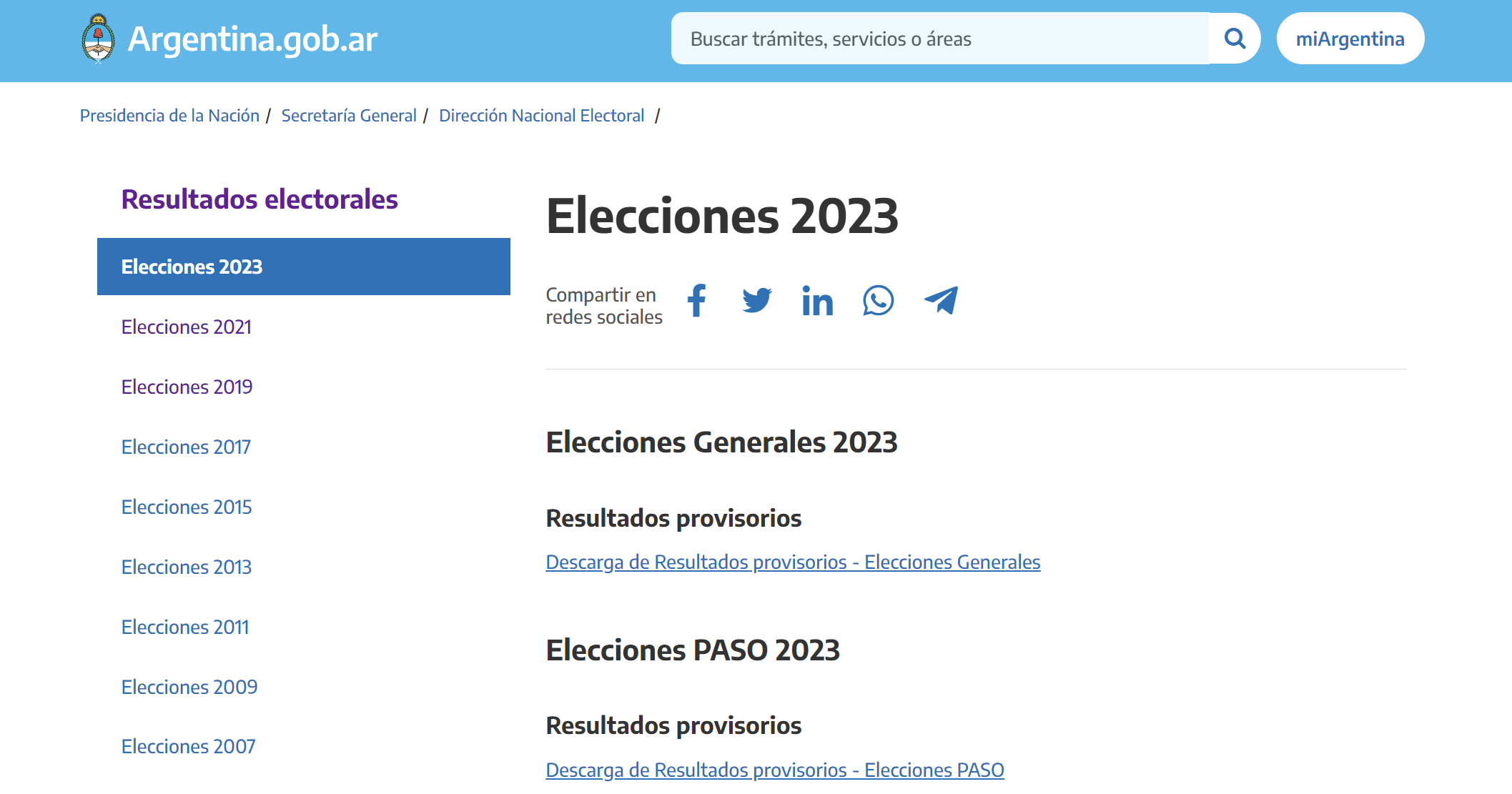
Allí encontraremos un link que nos redirige a una descarga de una carpeta zip. Lo que vamos a hacer a continuación, es automatizar la descarga, descompresión y carga de los datos en nuestra computadora.
Antes avanzar en el código, cabrá resaltar que nuestro país adhiere a una serie de cordadas internacionales en materia de apertura de datos y puede conseguirse una gran cantidad de data sobre una variedad de temas que pueden explorarse con técnicas como las que vamos a ver hoy.
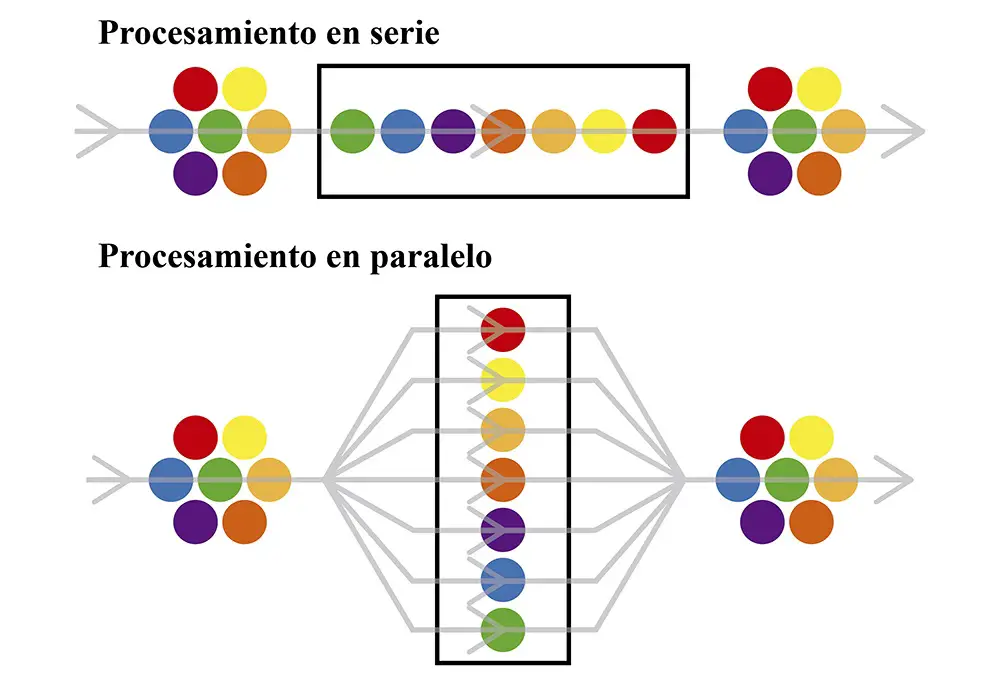
Como ya dijimos, la primera complejidad que presenta la lectura de estas datos es su tamaño. Para poder recuperarlos vamos a utilizar un método que se llama procesamiento paralelo, y lo que hace en definitiva es distribuir el peso del procesamiento del csv en los núcleos de nuestra pc, por ejemplo si tenemos una i5 podemos usar 5 núcleos de nuestro procesador.
Para esto vamos a descargar un paquete (hay varios que nos permiten hacer lo mismo), que se llama datatable y usar la función fread.
#install.packages("data.table") #instalamos la librearía
library(data.table)#levantamos
num_cores <- parallel::detectCores()# URL del archivo ZIP
url <- "https://www.argentina.gob.ar/sites/default/files/2023_generales.zip"
# Ruta local donde se guardará el archivo ZIP
zip_filepath <- "2023_generales.zip"
# Descargar el archivo ZIP
download.file(url, zip_filepath)
# Descomprimir el archivo ZIP
unzip(zip_filepath, exdir = "elecciones")
# Leer el archivo CSV usando fread
csv_filepath <- "elecciones/2023_Generales/ResultadosElectorales_2023.csv"
data <- fread(csv_filepath, nThread = num_cores)
# Ver las primeras filas del DataFrame
head(data) año eleccion_tipo recuento_tipo padron_tipo distrito_id
1: 2023 GENERAL PROVISORIO NORMAL 1
2: 2023 GENERAL PROVISORIO NORMAL 1
3: 2023 GENERAL PROVISORIO NORMAL 1
4: 2023 GENERAL PROVISORIO NORMAL 1
5: 2023 GENERAL PROVISORIO NORMAL 1
6: 2023 GENERAL PROVISORIO NORMAL 1
distrito_nombre seccionprovincial_id
1: Ciudad Autónoma de Buenos Aires 0
2: Ciudad Autónoma de Buenos Aires 0
3: Ciudad Autónoma de Buenos Aires 0
4: Ciudad Autónoma de Buenos Aires 0
5: Ciudad Autónoma de Buenos Aires 0
6: Ciudad Autónoma de Buenos Aires 0
seccionprovincial_nombre seccion_id seccion_nombre circuito_id
1: 1 Comuna 01 00018
2: 1 Comuna 01 00018
3: 1 Comuna 01 00018
4: 1 Comuna 01 00018
5: 1 Comuna 01 00018
6: 1 Comuna 01 00018
circuito_nombre mesa_id mesa_tipo mesa_electores cargo_id cargo_nombre
1: 00018 474 NATIVOS 343 1 PRESIDENTE Y VICE
2: 00018 474 NATIVOS 343 1 PRESIDENTE Y VICE
3: 00018 474 NATIVOS 343 1 PRESIDENTE Y VICE
4: 00018 474 NATIVOS 343 1 PRESIDENTE Y VICE
5: 00018 475 NATIVOS 349 1 PRESIDENTE Y VICE
6: 00018 475 NATIVOS 349 1 PRESIDENTE Y VICE
agrupacion_id agrupacion_nombre lista_numero lista_nombre votos_tipo
1: 0 0 NULO
2: 0 0 IMPUGNADO
3: 0 0 RECURRIDO
4: 0 0 COMANDO
5: 134 UNION POR LA PATRIA NA POSITIVO
6: 132 JUNTOS POR EL CAMBIO NA POSITIVO
votos_cantidad
1: 0
2: 0
3: 0
4: 0
5: 95
6: 59
Eliminamos el archivo zip, nos quedamos con el csv.
# Eliminar el archivo ZIP
file_removed_status <- file.remove(zip_filepath)
# Verificar si el archivo se eliminó correctamente
if (file_removed_status) {
print("El archivo ZIP ha sido eliminado con éxito.")
} else {
print("No se pudo eliminar el archivo ZIP.")
}[1] "El archivo ZIP ha sido eliminado con éxito."Hasta este punto, hemos logrado automatizar la descarga y procesamiento inicial de un conjunto de datos de gran tamaño, un desafío común en el análisis de datos electorales. Utilizando R y su capacidad para manejar procesamiento paralelo, hemos superado las limitaciones de las herramientas convencionales, preparando el terreno para un análisis más profundo y detallado de los datos electorales.
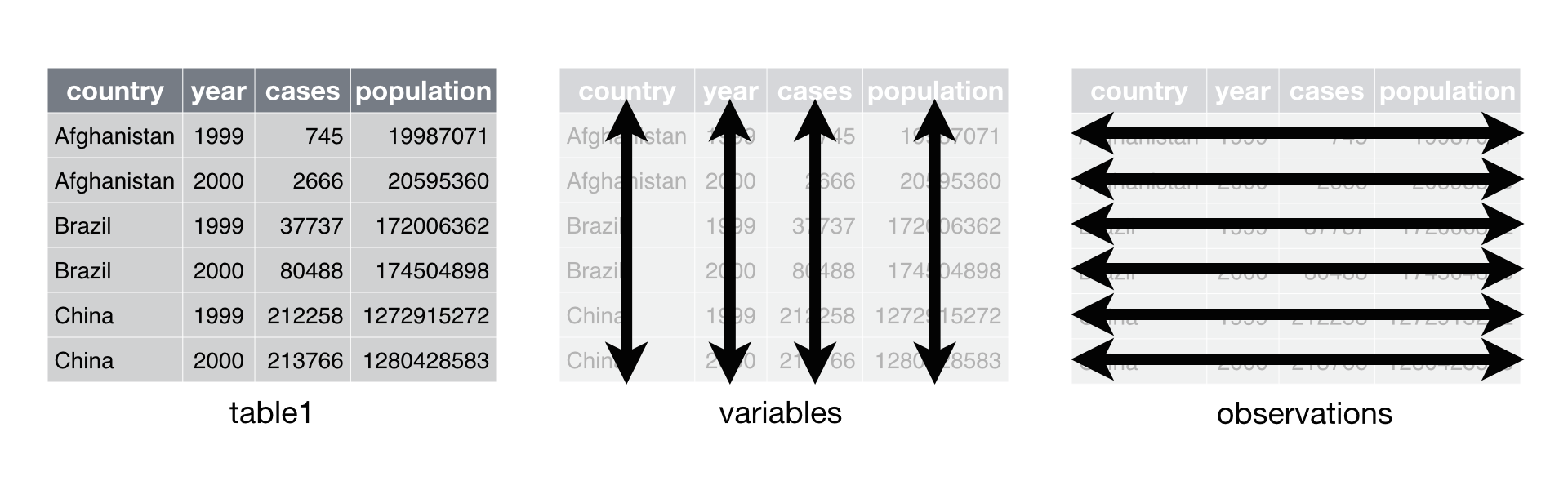
El paradigma tidy es un enfoque para organizar y estructurar los datos de una manera consistente, lo que facilita su manipulación y análisis.
En programación las “buenas prácticas” son importantes porque convivimos con muchos factores aleatorios que pueden hacernos incurrir en errores o perder tiempo desarrollo.
El paradigma tidy se basa en las siguientes premisas
Estructura Consistente: Los datos tidy siguen una estructura donde cada variable forma una columna, cada observación forma una fila, y cada tipo de unidad observacional forma una tabla. Esta consistencia facilita el análisis y la manipulación de los datos, ya que los patrones de datos se vuelven más predecibles y fáciles de entender.
Compatibilidad con Herramientas de Análisis: Los datos organizados según el paradigma tidy son más compatibles con las herramientas de análisis en R y otros lenguajes de programación. Por ejemplo, muchas funciones en R están diseñadas para trabajar de manera más eficiente con datos tidy.
Facilita la Visualización y Modelado: Los datos tidy simplifican el proceso de visualización y modelado. Por ejemplo, en R, ggplot2 y una variedad de modelos estadísticos funcionan mejor cuando los datos están en formato tidy.
Menos Preprocesamiento: Al tener una estructura de datos estandarizada, se reduce la necesidad de preprocesamiento y transformación de datos antes del análisis, lo que ahorra tiempo y esfuerzo.
Facilita la Comunicación de Resultados: Los datos organizados de manera tidy son más fáciles de explicar y presentar a otros, lo que facilita la comunicación de los hallazgos del análisis.
Operaciones Vectorizadas en R: Como R es un lenguaje de programación vectorizado, trabajar con datos tidy aprovecha esta característica. Las operaciones se pueden realizar de manera más eficiente y con menos código.
Manejo de Datos en el Mundo Real: En la práctica, los datos crudos rara vez están organizados de manera tidy. Aprender a transformar datos desordenados en datos tidy es una habilidad crucial, ya que prepara al científico de datos para trabajar con una variedad de formatos de datos en situaciones reales.
El siguiente esquema da cuenta de lo planteado gráficamente:
En R, un paquete (o librería) es una colección de funciones, conjuntos de datos y documentación empaquetados juntos. Los paquetes permiten extender la funcionalidad de R más allá de las funciones y características básicas que vienen con la instalación estándar. Uno de los conjuntos de paquetes más influyentes en R es el Tidyverse, que implementa el paradigma tidy, un enfoque coherente para la manipulación y visualización de datos.
El Tidyverse es un aliado indispensable en la tarea de limpiar y transformar datos, puesto que nos proporciona un conjunto de verbos (funciones) que permiten realizar operaciones comunes de manipulación de datos, como filtrar, seleccionar, transformar y resumir los datos. Estas operaciones se aplican de forma intuitiva y eficiente, lo que facilita la exploración y el análisis de nuestros datos.
El operador fundamental de la librería Tidyverse se llama pipe y se escribe así %>% o bien |>. Este operador es crucial para la eficiencia y legibilidad del código en R. Permite encadenar múltiples operaciones de manipulación de datos en una secuencia lógica y fácil de leer.
Por ejemplo, en lugar de anidar funciones, se pueden encadenar operaciones con el operador pipe, lo que hace que el código sea más limpio y comprensible. Esta característica es especialmente valiosa cuando se trabaja con conjuntos de datos complejos, como los que se encuentran en el análisis electoral, donde la claridad y la eficiencia son esenciales.
#%>%
#|>Otra ventaja es que tidyverse incluye paquetes adicionales como ggplot2, que facilita la creación de gráficos y visualizaciones atractivas y personalizadas. Esto es especialmente útil para presentar los resultados de la encuesta de manera clara y efectiva.
str(data) #str es una función rapida que resume las variables de nuestro datasetClasses 'data.table' and 'data.frame': 5868102 obs. of 23 variables:
$ año : int 2023 2023 2023 2023 2023 2023 2023 2023 2023 2023 ...
$ eleccion_tipo : chr "GENERAL" "GENERAL" "GENERAL" "GENERAL" ...
$ recuento_tipo : chr "PROVISORIO" "PROVISORIO" "PROVISORIO" "PROVISORIO" ...
$ padron_tipo : chr "NORMAL" "NORMAL" "NORMAL" "NORMAL" ...
$ distrito_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ distrito_nombre : chr "Ciudad Autónoma de Buenos Aires" "Ciudad Autónoma de Buenos Aires" "Ciudad Autónoma de Buenos Aires" "Ciudad Autónoma de Buenos Aires" ...
$ seccionprovincial_id : int 0 0 0 0 0 0 0 0 0 0 ...
$ seccionprovincial_nombre: chr "" "" "" "" ...
$ seccion_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ seccion_nombre : chr "Comuna 01" "Comuna 01" "Comuna 01" "Comuna 01" ...
$ circuito_id : chr "00018" "00018" "00018" "00018" ...
$ circuito_nombre : chr "00018" "00018" "00018" "00018" ...
$ mesa_id : int 474 474 474 474 475 475 475 475 475 475 ...
$ mesa_tipo : chr "NATIVOS" "NATIVOS" "NATIVOS" "NATIVOS" ...
$ mesa_electores : int 343 343 343 343 349 349 349 349 349 349 ...
$ cargo_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ cargo_nombre : chr "PRESIDENTE Y VICE" "PRESIDENTE Y VICE" "PRESIDENTE Y VICE" "PRESIDENTE Y VICE" ...
$ agrupacion_id : int 0 0 0 0 134 132 135 136 133 0 ...
$ agrupacion_nombre : chr "" "" "" "" ...
$ lista_numero : int 0 0 0 0 NA NA NA NA NA 0 ...
$ lista_nombre : chr "" "" "" "" ...
$ votos_tipo : chr "NULO" "IMPUGNADO" "RECURRIDO" "COMANDO" ...
$ votos_cantidad : int 0 0 0 0 95 59 57 9 4 4 ...
- attr(*, ".internal.selfref")=<externalptr> #unique(ba_tercera$Agrupacion)qué vemos?
Ahora que verificamos que la data está ok y que es la que necesitamos, usemos algunas funciones de tidyverse con nuestros datos para ver cómo funciona el paradigma aplicado a nuestro objetivo que es rearmar y visualizar los resultados de la elección para la categoría intendente en el Municipio de Lanús.
Levantamos tidyverse y utilizamos la función filter para filtrar los datos que nos interesan.
#install.packages("tidyverse")
library(tidyverse)
#exploramos sin crear un objeto
data_lanus<-data %>% #operador pipe, encadena operaciones
# Filtramos solamente las filas donde el valor de la columna "seccion" es "gp".
filter(seccion_nombre == "Lanús") Que categorías estuvieron en juego en las elecciones generales 2023?
data_lanus %>%
group_by(cargo_nombre) %>% #agrupapamos por cargo
count() #contamos# A tibble: 8 × 2
# Groups: cargo_nombre [8]
cargo_nombre n
<chr> <int>
1 DIPUTADO NACIONAL 9756
2 GOBERNADOR Y VICE 10287
3 INTENDENTE 10287
4 PARLAMENTO MERCOSUR NACIONAL 10840
5 PARLAMENTO MERCOSUR REGIONAL 9756
6 PRESIDENTE Y VICE 10840
7 SENADOR NACIONAL 9756
8 SENADOR PROVINCIAL 10287Guardamos en un objeto los datos correspondientes a Lanús, para la categoría Intendente.
int_lanus <-data_lanus %>% #operador pipe, encadena operaciones
filter(cargo_nombre=="INTENDENTE") #agregamos otra accionCon select generamos una selección de variables que nos pueden sernos de valor para nuestra interpretación de los datos, por ejemplo las listas y la cantidad de votos:
int_select <- int_lanus %>%
select(circuito_id, mesa_id,agrupacion_nombre, votos_cantidad, votos_tipo)
head(int_select) circuito_id mesa_id agrupacion_nombre
1: 00259 1 UNION POR LA PATRIA
2: 00259 1 JUNTOS POR EL CAMBIO
3: 00259 1 LA LIBERTAD AVANZA
4: 00259 1 FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD
5: 00259 1
6: 00259 1
votos_cantidad votos_tipo
1: 114 POSITIVO
2: 87 POSITIVO
3: 45 POSITIVO
4: 13 POSITIVO
5: 26 EN BLANCO
6: 0 NULOEn nuestro dataframe tenemos un campo vacío que se corresponde con los votos positivos y el resto de categorías a blancos, etc. Transformemos ese campo libre en una nueva categoría sea “otro” para terminar de ordenar los datos y ganar en comprensión.
Para eso vamos a usar dos funciones muy importantes en tidyverse: mutate y casewhen.
La función mutate en R es esencial para modificar data frames. Permite tanto crear nuevas columnas como alterar las existentes. Al aplicar mutate, proporcionamos un data frame y luego especificamos las transformaciones deseadas. Por ejemplo, puedes añadir una columna que sea el resultado de una operación matemática aplicada a otras columnas, o modificar una columna existente para ajustar sus valores. mutate es altamente eficiente y flexible, facilitando la personalización y el enriquecimiento de tus datos.
case_when, por su parte es una función de transformación condicional, utilizada dentro de mutate para aplicar diferentes cálculos o cambios basados en condiciones específicas. Funciona como una serie de sentencias “si-entonces” (similar a “if-else” en otros lenguajes de programación). Cada condición se verifica en orden, y la primera que se cumple determina el valor que se asignará a la columna. Esto es particularmente útil para recategorizar datos, llenar valores vacíos con categorías específicas, o aplicar transformaciones complejas basadas en múltiples criterios.
El código que sigue en R utiliza mutate junto con case_when para modificar el data frame _select. Aquí, se crea o actualiza la columna Agrupacion_ok. Si agrupacion_nombre está vacío, se asigna el valor “otro” a Agrupacion_ok. Si agrupacion_nombre contiene algún valor, se mantiene ese valor en Agrupacion_ok. Esto asegura que todos los registros tengan una categoría válida en Agrupacion_ok, reemplazando los vacíos con “otro”.
int_select <- int_select %>%
mutate(Agrupacion_ok = case_when(
agrupacion_nombre == "" ~ "otro", # Si el valor de Agrupacion es vacío, se asigna "otro"
TRUE ~ agrupacion_nombre # Si no es vacío, se mantiene el valor original de Agrupacion
))El proceso de limpieza y ordenamiento de datos podemos pensarlo como el torneado de una pieza, que en este caso es nuestro objeto de estudio.

Para comprender mejor el impacto y la distribución de los votos por fuerza política en un conjunto de datos electorales, utilizamos la función summarise de Tidyverse, que nos permite realizar operaciones de resumen y agregación, transformando grandes volúmenes de información en estadísticas significativas y manejables.
Una de las principales aplicaciones de summarise es calcular la suma total de una variable numérica, como la cantidad total de votos obtenidos por cada partido político. Esto nos da una visión clara y directa del peso electoral de cada fuerza en el conjunto de datos. Además, summarise puede ser utilizado para determinar promedios, lo que nos ayuda a entender las tendencias generales en los datos, como el promedio de votos por mesa o circuito.
Veamos cómo opera en la práctica esta función generando una primera síntesis de cantidad de votos emitidos en Lanús para la categoría intendente:
votos_total<- int_select %>%
summarise(n_seleccion=sum(votos_cantidad))
votos_total n_seleccion
1 298259Cuántos votos fueron positivos?
votos_afirmativos <- int_select %>%
filter(votos_tipo=="POSITIVO") %>% #primero filtramos
summarise(n_total=sum(votos_cantidad)) #despues resumimos
votos_afirmativos n_total
1 276352Cuantos votos no fueron positivos?
votos_total-votos_afirmativos #calculadora, restamos dos objetos n_seleccion
1 21907Otra funcionalidad clave de summarise es su capacidad para trabajar en conjunto con la función group_by. Esta combinación nos permite agrupar los datos según categorías específicas, como por ejemplo, por distrito electoral o por tipo de elección, y luego aplicar funciones de resumen a cada grupo. Esto es esencial para analizar cómo se distribuyen los votos en diferentes segmentos y para identificar patrones o anomalías en los datos.
Votos por fuerza política (resumen agrupado):
# Se crea un nuevo objeto llamado "votosxagrup" para almacenar los resultados del análisis de votos por agrupación en el partido de gp.
votosxagrup <- int_select %>%
group_by(Agrupacion_ok) %>% # La función group_by() se utiliza para agrupar los datos por la variable "Agrupacion". Esto permitirá realizar cálculos separados para cada agrupación.
summarise(n=sum(votos_cantidad)) %>% # La función summarise() se utiliza para calcular la suma de los votos para cada agrupación. El resultado se guarda en una nueva columna llamada "n_votos".
arrange(desc(n))# El código concluye mostrando el objeto "votosxagrup", que contiene la tabla resultante con las agrupaciones y la suma de votos para cada una.
print(votosxagrup)# A tibble: 5 × 2
Agrupacion_ok n
<chr> <int>
1 UNION POR LA PATRIA 123300
2 JUNTOS POR EL CAMBIO 95983
3 LA LIBERTAD AVANZA 45429
4 otro 21907
5 FRENTE DE IZQUIERDA Y DE TRABAJADORES - UNIDAD 11640Veamos una transformación importante relacionado a la generación de estadísticas descriptivas.
lanus_por <- int_select %>%
filter(votos_tipo=="POSITIVO") %>% #primero filtramos
group_by(Agrupacion_ok) %>%
# Calcula la suma de los votos para cada agrupación.
summarise(votos_agrupacion = sum(votos_cantidad)) %>%
# Calcula el total de votos sumando los votos de todas las agrupaciones.
mutate(totales = sum(votos_agrupacion),
# Calcula el porcentaje de votos de cada agrupación en relación al total de votos.
porc_agrupacion = round(100 * votos_agrupacion / totales, 1))
# Imprime los resultados de los votos por agrupación y los porcentajes correspondientes.
lanus_por# A tibble: 4 × 4
Agrupacion_ok votos_agrupacion totales porc_agrupacion
<chr> <int> <int> <dbl>
1 FRENTE DE IZQUIERDA Y DE TRABAJADORE… 11640 276352 4.2
2 JUNTOS POR EL CAMBIO 95983 276352 34.7
3 LA LIBERTAD AVANZA 45429 276352 16.4
4 UNION POR LA PATRIA 123300 276352 44.6Constrastamos con los resultados provistos por:
https://resultados.gob.ar/elecciones/10/95/1/-1/-1/Buenos-Aires/Secci%C3%B3n-Tercera/Lan%C3%BAs#agrupaciones
Nos da ok el n, pero el porcentaje no ya que en las elecciones se ponderan solo los votos afirmativos.
Rehagamos nuestro codigo prestando atención a esta particularidad
lanus_por <- int_select %>%
filter(!Agrupacion_ok=="otro") %>%
group_by(Agrupacion_ok) %>%
# Calcula la suma de los votos para cada agrupación.
summarise(votos_agrupacion = sum(votos_cantidad)) %>%
# Calcula el total de votos sumando los votos de todas las agrupaciones.
mutate(totales = sum(votos_agrupacion),
# Calcula el porcentaje de votos de cada agrupación en relación al total de votos.
porc_agrupacion = round(100 * votos_agrupacion / totales, 1))
# Imprime los resultados de los votos por agrupación y los porcentajes correspondientes.
lanus_por# A tibble: 4 × 4
Agrupacion_ok votos_agrupacion totales porc_agrupacion
<chr> <int> <int> <dbl>
1 FRENTE DE IZQUIERDA Y DE TRABAJADORE… 11640 276352 4.2
2 JUNTOS POR EL CAMBIO 95983 276352 34.7
3 LA LIBERTAD AVANZA 45429 276352 16.4
4 UNION POR LA PATRIA 123300 276352 44.6Agrupando además por circuito, podremos replicar las métricas para cada territorio en particular. Así podríamos por ejemplo conocer en que zona de Lanús Unión por la Patria obtuvo mayor porcentaje de votos.
lanus_por_circuitos <- int_select %>%
filter(!Agrupacion_ok=="otro") %>%
group_by(circuito_id, Agrupacion_ok) %>%
# Calcula la suma de los votos para cada agrupación por circuito.
summarise(votos_agrupacion = sum(votos_cantidad)) %>%
# Calcula el total de votos sumando los votos de todas las agrupaciones.
mutate(totales = sum(votos_agrupacion),
# Calcula el porcentaje de votos de cada agrupación en relación al total de votos.
porc_agrupacion = round(100 * votos_agrupacion / totales, 1))
# Imprime los resultados de los votos por agrupación para cada circuito y los porcentajes correspondientes.
lanus_por_circuitos# A tibble: 52 × 5
# Groups: circuito_id [13]
circuito_id Agrupacion_ok votos_agrupacion totales porc_agrupacion
<chr> <chr> <int> <int> <dbl>
1 00259 FRENTE DE IZQUIERDA Y D… 324 6855 4.7
2 00259 JUNTOS POR EL CAMBIO 2604 6855 38
3 00259 LA LIBERTAD AVANZA 1178 6855 17.2
4 00259 UNION POR LA PATRIA 2749 6855 40.1
5 00260 FRENTE DE IZQUIERDA Y D… 1073 25368 4.2
6 00260 JUNTOS POR EL CAMBIO 10503 25368 41.4
7 00260 LA LIBERTAD AVANZA 3848 25368 15.2
8 00260 UNION POR LA PATRIA 9944 25368 39.2
9 00261 FRENTE DE IZQUIERDA Y D… 1137 25904 4.4
10 00261 JUNTOS POR EL CAMBIO 8476 25904 32.7
# ℹ 42 more rowsCreamos el objeto que contenga el circuito donde Unión por la Patria sacó mayor porcentaje de votos
# Encontrar el circuito donde "Unión por la Patria" obtuvo la mayor cantidad de votos
circuito_max_votos_up <- lanus_por_circuitos %>%
filter(Agrupacion_ok == "UNION POR LA PATRIA") %>%
group_by(circuito_id) %>%
arrange(desc(porc_agrupacion)) %>%
head(1)
# Guardar el nombre del circuito con más votos
circuito_maximo <- circuito_max_votos_up$circuito_id
# Filtrar todas las fuerzas políticas de ese circuito
fuerzas_en_circuito_maximo <- lanus_por_circuitos %>%
filter(circuito_id == circuito_maximo)
# Mostrar los resultados
print(fuerzas_en_circuito_maximo)# A tibble: 4 × 5
# Groups: circuito_id [1]
circuito_id Agrupacion_ok votos_agrupacion totales porc_agrupacion
<chr> <chr> <int> <int> <dbl>
1 00262 FRENTE DE IZQUIERDA Y DE… 1532 41428 3.7
2 00262 JUNTOS POR EL CAMBIO 10346 41428 25
3 00262 LA LIBERTAD AVANZA 6722 41428 16.2
4 00262 UNION POR LA PATRIA 22828 41428 55.1Felicitaciones a lxs militantes del circuito 262.
El paquete squisse de R es una herramienta que se utiliza para el análisis y la visualización de datos de encuestas.
#install.packages("esquisse")
#esquisse::esquisser(gp_agrupaciones)Esquisse nos genera un código en ggplot, una librería de R para visualizar datos.
ggplot(lanus_por) +
aes(x = Agrupacion_ok, y = porc_agrupacion) +
geom_col(fill = "orange") +
coord_flip() +
theme_classic()
La visualización de datos es esencial para comprender la complejidad de los conjuntos de datos electorales. En el gráfico de barras que hemos creado, cada barra representa una agrupación política y su altura corresponde al porcentaje de votos que recibió esa agrupación. Este tipo de gráfico es particularmente útil para identificar rápidamente qué agrupaciones tuvieron un mejor desempeño en las elecciones.
Veamos un grafico mas prolijo
lanus_por%>%
ggplot() +
aes(x = reorder(Agrupacion_ok, porc_agrupacion), y = porc_agrupacion) +
geom_col(fill = "orange") +
geom_text(aes(label = scales::percent(porc_agrupacion/100, accuracy = 1)),
position = position_dodge(width = 0.9), hjust = -0.1) +
coord_flip() +
theme_classic() +
labs(title =
"Porcentaje de Votos por Agrupación en Lanús",
x = "Agrupación Política",
y = "Porcentaje de Votos",
caption = "Fuente: CNE Elecciones generales 2023") +
theme(plot.title = element_text(hjust = 0.5))
En este código, reorder(Agrupacion_ok, porc_agrupacion) ordena las barras de acuerdo con el porcentaje de votos. geom_text() añade las etiquetas con los porcentajes al lado de cada barra. Tambuen sumamos
y ahora un grafico facetado
lanus_por_circuitos%>%
ggplot() +
aes(x = reorder(Agrupacion_ok, porc_agrupacion), y = porc_agrupacion) +
geom_col(fill = "orange") +
facet_wrap(~circuito_id) + # Reemplaza 'distrito' con el nombre de tu columna
coord_flip() +
theme_classic() +
labs(title = "Porcentaje de Votos por Agrupación en Diferentes Distritos",
x = "Agrupación Política",
y = "Porcentaje de Votos",
caption = "Fuente: Datos Electorales") +
theme(plot.title = element_text(hjust = 0.5))
Un gráfico facetado en R, utilizando la librería ggplot2, es una técnica de visualización que permite dividir un conjunto de datos en múltiples gráficos pequeños, todos colocados en la misma imagen. Cada uno de estos gráficos, llamados facetas, representa una porción o subconjunto del conjunto de datos total, basado en una categoría específica. Por ejemplo, si tienes datos de votación de diferentes regiones, puedes crear un gráfico facetado donde cada faceta muestra los resultados de una región específica. Esto facilita la comparación directa entre las regiones, manteniendo una coherencia en la escala y el diseño de cada gráfico.
Uso de R y Tidyverse: Hemos visto cómo R y el conjunto de paquetes de Tidyverse pueden simplificar significativamente el análisis de datos electorales.
Estructura de los Datos: La estructura “tidy” de los datos facilita la manipulación y el análisis, permitiendo filtrar, transformar y resumir los datos de manera eficiente.
Insights Electorales: A través del análisis y la visualización de los datos, pudimos obtener una visión clara de la distribución de votos entre diferentes agrupaciones políticas.
Análisis Temporal: Sería interesante extender este análisis para incluir datos de elecciones anteriores y examinar cómo han cambiado las tendencias políticas a lo largo del tiempo.
Predicciones y Modelos: podríamos usar estos datos para entrenar modelos predictivos que podrían ser útiles para anticipar los resultados de futuras elecciones.
Con estos pasos, no solo tendríamos un análisis completo del pasado y el presente electoral, sino también herramientas para explorar posibles futuros escenarios. Este enfoque holístico hace que el análisis de datos electorales sea una herramienta poderosa para cualquier persona interesada en la dinámica política.
Gracias por el tiempo!
@online{pedro_damian_orden2023,
author = {Pedro Damian Orden, Lic.},
title = {Intro a {R} Aplicado Al Análisis de Los Datos Abiertos de Las
{Elecciones} {Generales} 2023},
date = {2023-11-15},
url = {https://tecysoc.netlify.app/posts/Clase abierta generales 2023/},
langid = {en}
}